

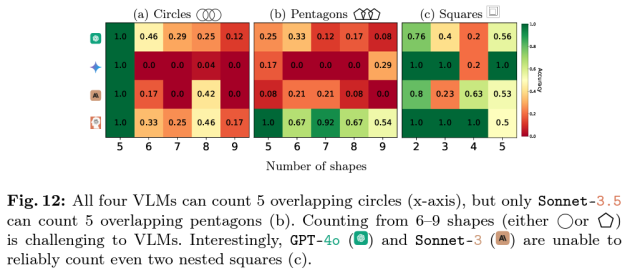

Even small changes to the tasks could also lead to huge changes in results. While all four tested models were able to correctly identify five overlapping hollow circles, the accuracy across all models dropped to well below 50 percent when six to nine circles were involved. The researchers hypothesize that this “suggests that VLMs are biased towards the well-known Olympic logo, which has 5 circles.” In other cases, models occasionally hallucinated nonsensical answers, such as guessing “9,” “n”, or “©” as the circled letter in the word “Subdermatoglyphic.”
Overall, the results highlight how AI models that can perform well at high-level visual reasoning have some significant “blind spots” (sorry) when it comes to low-level abstract images. It’s all somewhat reminiscent of similar capability gaps that we often see in state-of-the-art large language models, which can create extremely cogent summaries of lengthy texts while at the same time failing extremely basic math and spelling questions.
These gaps in VLM capabilities could come down to the inability of these systems to generalize beyond the kinds of content they are explicitly trained on. Yet when the researchers tried fine-tuning a model using specific images drawn from one of their tasks (the “are two circles touching?” test), that model showed only modest improvement, from 17 percent accuracy up to around 37 percent. “The loss values for all these experiments were very close to zero, indicating that the model overfits the training set but fails to generalize,” the researchers write.
The researchers propose that the VLM capability gap may be related to the so-called “late fusion” of vision encoders onto pre-trained large language models. An “early fusion” training approach that integrates visual encoding alongside language training could lead to better results on these low-level tasks, the researchers suggest (without providing any sort of analysis of this question).



