
Credit:
Zhu, et al
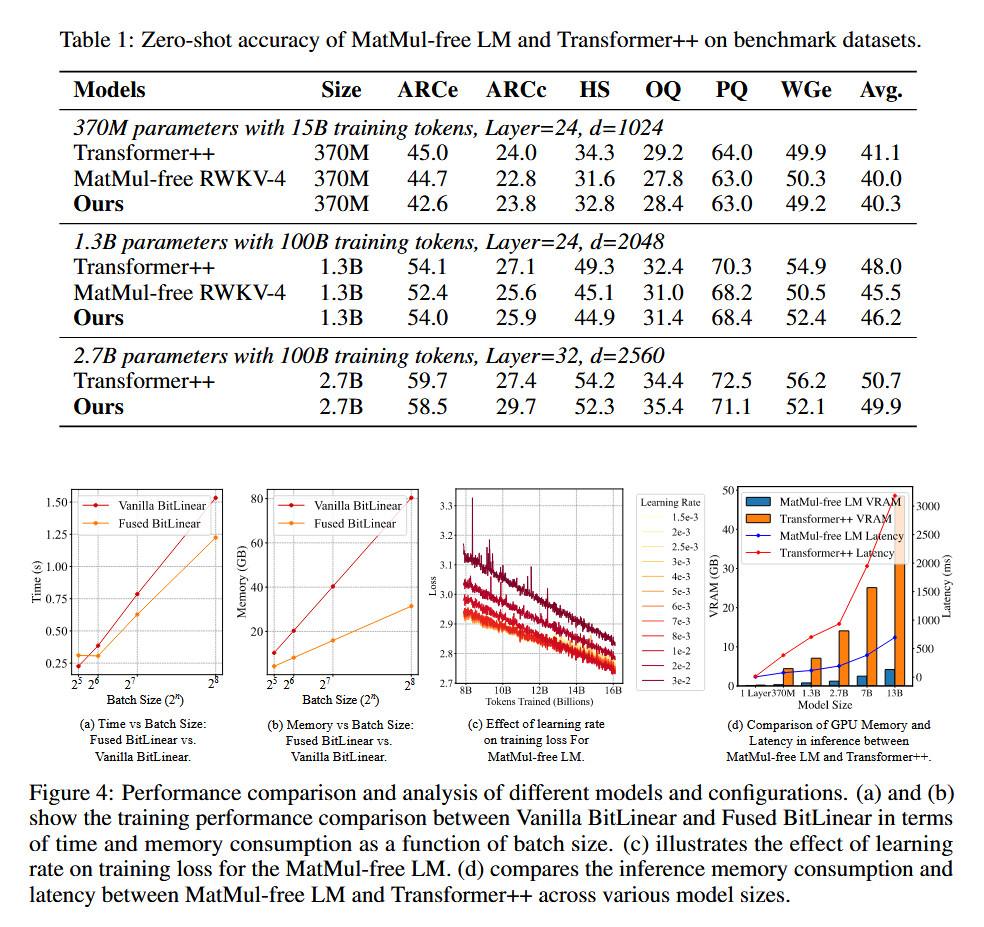
To evaluate their approach, the researchers compared their MatMul-free LM against a reproduced Llama-2-style model (which they call “Transformer++”) across three model sizes: 370M, 1.3B, and 2.7B parameters. All models were pre-trained on the SlimPajama dataset, with the larger models trained on 100 billion tokens each. Researchers claim the MatMul-free LM achieved competitive performance against the Llama 2 baseline on several benchmark tasks, including answering questions, commonsense reasoning, and physical understanding.
In addition to power reductions, the researchers’ MatMul-free LM significantly reduced memory usage. Their optimized GPU implementation decreased memory consumption by up to 61 percent during training compared to an unoptimized baseline.
To be clear, a 2.7B parameter Llama-2 model is a long way from the current best LLMs on the market, such as GPT-4, which is estimated to have over 1 trillion parameters in aggregate. GPT-3 shipped with 175 billion parameters in 2020. Parameter count generally means more complexity (and, roughly, capability) baked into the model, but at the same time, researchers have been finding ways to achieve higher-level LLM performance with fewer parameters.
So, we’re not talking ChatGPT-level processing capability here yet, but the UC Santa Cruz technique does not necessarily preclude that level of performance, given more resources.
Extrapolating into the future
The researchers say that scaling laws observed in their experiments suggest that the MatMul-free LM may also outperform traditional LLMs at very large scales. The researchers project that their approach could theoretically intersect with and surpass the performance of standard LLMs at scales around 10²³ FLOPS, which is roughly equivalent to the training compute required for models like Meta’s Llama-3 8B or Llama-2 70B.
However, the authors note that their work has limitations. The MatMul-free LM has not been tested on extremely large-scale models (e.g., 100 billion-plus parameters) due to computational constraints. They call for institutions with larger resources to invest in scaling up and further developing this lightweight approach to language modeling.
The article was updated on June 26, 2024 at 9:20 AM to remove an inaccurate power estimate related to running a LLM locally on a RTX 3060 created by the author.



